Ever heard a synth talk? If you have, it's due to formant synthesis. Gordon Reid explores the theory of analogue formant synthesis, how it relates to the human voice and modern digital synths like Yamaha's FS1R.
Last month (SOS February 2001), we discussed a way of emulating acoustic musical instruments using short delay lines such as spring reverbs and analogue reverb/echo units. At the end of that article, I posed the following question: "Couldn't we have avoided this talk of echoes, RT60s, room modes, and all that other stuff, and achieved the same result with a bunch of fixed (or 'formant') filters?". This month, we're going to answer that question.
A Little More On Filters
![Figure 1(a): [left-top] 6dB/octave low-pass filter. Figure 1(b): [right-top] 6dB/octave high-pass filter. Figure 1(c): [left-bottom] Band-reject filter. Figure 1(d): [right-bottom] Band-pass filter.](https://dt7v1i9vyp3mf.cloudfront.net/styles/news_large/s3/imagelibrary/s/synth1-0301-rrc4CvGayZNftYSdupwej.4qF2N79zLD.gif "Figure 1(a): [left-top] 6dB/octave low-pass filter. Figure 1(b): [right-top] 6dB/octave high-pass filter. Figure 1(c): [left-bottom] Band-reject filter. Figure 1(d): [right-bottom] Band-pass filter.") Figure 1(a): [left-top] 6dB/octave low-pass filter. Figure 1(b): [right-top] 6dB/octave high-pass filter. Figure 1(c): [left-bottom] Band-reject filter. Figure 1(d): [right-bottom] Band-pass filter. Let's start by remembering the four types of filters that I first described in Parts 4, 5 and 6 of this series (SOS August to October 1999). These are the low-pass filter, the high-pass filter, the band-reject filter, and the band-pass filter (see Figures 1(a)-(d)). OK, we're all sick to the back teeth of descriptions of the low-pass and high-pass filters in conventional synthesis. No matter. This month we're going to concentrate on the band-pass filter (or BPF), so read on...
Figure 1(a): [left-top] 6dB/octave low-pass filter. Figure 1(b): [right-top] 6dB/octave high-pass filter. Figure 1(c): [left-bottom] Band-reject filter. Figure 1(d): [right-bottom] Band-pass filter. Let's start by remembering the four types of filters that I first described in Parts 4, 5 and 6 of this series (SOS August to October 1999). These are the low-pass filter, the high-pass filter, the band-reject filter, and the band-pass filter (see Figures 1(a)-(d)). OK, we're all sick to the back teeth of descriptions of the low-pass and high-pass filters in conventional synthesis. No matter. This month we're going to concentrate on the band-pass filter (or BPF), so read on...
 Figure 2: Placing a number of band-pass filters in series.Imagine that we place several of the band-pass filters shown in 1(d) in series (see Figure 2). It should be obvious that at the peak, the signal remains unaffected. After all, a gain change of 0dB remains a gain change of 0dB no matter how many times you apply it. But in the 'skirt' of the filter, the gain drops increasingly quickly as you add more filters to the signal path (see Figures 3(a) and 3(b)).
Figure 2: Placing a number of band-pass filters in series.Imagine that we place several of the band-pass filters shown in 1(d) in series (see Figure 2). It should be obvious that at the peak, the signal remains unaffected. After all, a gain change of 0dB remains a gain change of 0dB no matter how many times you apply it. But in the 'skirt' of the filter, the gain drops increasingly quickly as you add more filters to the signal path (see Figures 3(a) and 3(b)).
![Figure 3(a) [left]: The response of placing two 1-pole band-pass filters in series. Figure 3(b) [right]: The response of placing four 1-pole band-pass filters in series.](https://dt7v1i9vyp3mf.cloudfront.net/styles/news_large/s3/imagelibrary/s/synth3-0301-7IbKAgmQMMwbwVi6mtgO_fet9DEcxUQA.gif "Figure 3(a) [left]: The response of placing two 1-pole band-pass filters in series. Figure 3(b) [right]: The response of placing four 1-pole band-pass filters in series.") Figure 3(a) [left]: The response of placing two 1-pole band-pass filters in series. Figure 3(b) [right]: The response of placing four 1-pole band-pass filters in series.As you can see, the band-pass region of the combined filter tightens up considerably as you add more filters to the series. This, of course, is directly analogous to the situation wherein we add more poles to a low-pass filter circuit to increase the cut-off rate from 6dB/octave to 12dB/octave, 18dB/octave, 24dB/octave... and so on.
Figure 3(a) [left]: The response of placing two 1-pole band-pass filters in series. Figure 3(b) [right]: The response of placing four 1-pole band-pass filters in series.As you can see, the band-pass region of the combined filter tightens up considerably as you add more filters to the series. This, of course, is directly analogous to the situation wherein we add more poles to a low-pass filter circuit to increase the cut-off rate from 6dB/octave to 12dB/octave, 18dB/octave, 24dB/octave... and so on.
 Figure 4: Configuring a number of band-pass filters in parallel.Now let's look at the case in which we place the band-pass filters in parallel rather than in series (see Figure 4). If we set the centre frequency 'Fc' of all the filters to be the same, the result is no different from using a single filter and, depending upon the make-up gain in the mixer, will look like Figure 1(d). Much more interesting is the response when you set Fc to be different for each filter. You then obtain the result shown below in Figure 6(a). As you can see, the broad responses overlap considerably, giving rise to a frequency response with many small bumps in the pass-band (the pass-band is so-called because it is the range of frequencies in which the signal can pass relatively unaffected through the system). Outside the pass-band, the gain tapers off until, at the extremes, little signal passes.
Figure 4: Configuring a number of band-pass filters in parallel.Now let's look at the case in which we place the band-pass filters in parallel rather than in series (see Figure 4). If we set the centre frequency 'Fc' of all the filters to be the same, the result is no different from using a single filter and, depending upon the make-up gain in the mixer, will look like Figure 1(d). Much more interesting is the response when you set Fc to be different for each filter. You then obtain the result shown below in Figure 6(a). As you can see, the broad responses overlap considerably, giving rise to a frequency response with many small bumps in the pass-band (the pass-band is so-called because it is the range of frequencies in which the signal can pass relatively unaffected through the system). Outside the pass-band, the gain tapers off until, at the extremes, little signal passes.
![Figure 5: [top] Adding BPFs to create a sharper filter response in each signal path. Figure 6(a): [left-bottom] Configuring single-pole BPFs in parallel. Figure 6(b): [right-bottom] Configuring multi-pole BPFs in parallel.](https://dt7v1i9vyp3mf.cloudfront.net/styles/news_large/s3/imagelibrary/s/synth5_6-0301-GIYQOjwya9a4ZxMfkkcH094gHQvQD4pX.gif "Figure 5: [top] Adding BPFs to create a sharper filter response in each signal path. Figure 6(a): [left-bottom] Configuring single-pole BPFs in parallel. Figure 6(b): [right-bottom] Configuring multi-pole BPFs in parallel.") Figure 5: [top] Adding BPFs to create a sharper filter response in each signal path. Figure 6(a): [left-bottom] Configuring single-pole BPFs in parallel. Figure 6(b): [right-bottom] Configuring multi-pole BPFs in parallel. Let's now add more BPFs to each signal path (see Figure 5) to sharpen the responses. Provided that the centre frequencies of each of the filters in a given path are the same (I've labelled these f1, f2 and f3) but are different from those of the other paths, we obtain three distinct peaks in the spectrum, as shown in Figure 6(b). The filters severely attenuate any signal lying outside these narrow pass-bands, and the output takes on a distinctive new character.
Figure 5: [top] Adding BPFs to create a sharper filter response in each signal path. Figure 6(a): [left-bottom] Configuring single-pole BPFs in parallel. Figure 6(b): [right-bottom] Configuring multi-pole BPFs in parallel. Let's now add more BPFs to each signal path (see Figure 5) to sharpen the responses. Provided that the centre frequencies of each of the filters in a given path are the same (I've labelled these f1, f2 and f3) but are different from those of the other paths, we obtain three distinct peaks in the spectrum, as shown in Figure 6(b). The filters severely attenuate any signal lying outside these narrow pass-bands, and the output takes on a distinctive new character.
A Little More On Modelling
If the frequency response in Figure 6(b) looks familiar, let me refer you back to last month's SOS and, in particular, the diagram reproduced here as Figure 7. This is the frequency response of a set of 'modes' which, as we discovered last month, may be the result of passing the signal through a delay unit such as a spring reverb or bucket-brigade device. It also represents a single set of the 'room modes' that arise as a consequence of the sound bouncing around inside a reverberant chamber.
![Figure 7: [top] A family of modes. Figure 8: [bottom] Using multiple band-pass filters (BPFs) to create three families of modes.](https://dt7v1i9vyp3mf.cloudfront.net/styles/news_large/s3/imagelibrary/s/synth7_8-0301-7Jk5AV6lBikgD7KSBo6Ddn.bsoKNtype.gif "Figure 7: [top] A family of modes. Figure 8: [bottom] Using multiple band-pass filters (BPFs) to create three families of modes.") Figure 7: [top] A family of modes. Figure 8: [bottom] Using multiple band-pass filters (BPFs) to create three families of modes.OK, so Figures 6(b) and 7 look rather different, but it's not too difficult to design and configure a set of band-pass filters that responds similarly to Figure 7. You may need to add a 'bypass' path to ensure that an appropriate amount of signal passes between pass-bands, but we're going to ignore that. Furthermore, if the Fcs are precise (and this is yet another instance of the phenomenon known as time/frequency duality, discussed last month) the filter-bank will impose the appropriate set of delays upon any signal passed through it.
Figure 7: [top] A family of modes. Figure 8: [bottom] Using multiple band-pass filters (BPFs) to create three families of modes.OK, so Figures 6(b) and 7 look rather different, but it's not too difficult to design and configure a set of band-pass filters that responds similarly to Figure 7. You may need to add a 'bypass' path to ensure that an appropriate amount of signal passes between pass-bands, but we're going to ignore that. Furthermore, if the Fcs are precise (and this is yet another instance of the phenomenon known as time/frequency duality, discussed last month) the filter-bank will impose the appropriate set of delays upon any signal passed through it.
You may also recall that, last month, we used three delay units to achieve a superficial emulation of a three-dimensional space. We then shortened the delay times of each unit until the dimensions of our 'virtual' reverberant chamber were no larger than the body of a guitar or violin. It's a small leap of intuition, therefore, to realise that we could use three banks of band-pass filters to achieve the same effect (see Figure 8).
The most important thing about this configuration is that the frequency response of the filter banks, and the timbre that they therefore impose on the signal, is independent of the pitch of the source. To see how this differs from conventional synthesizer filtering (in which the filter cutoff frequency often tracks the pitch of the note being played) consider Figures 9 and 10.
![Figure 9: [top] A 100Hz signal played through a system with Fcs at 400Hz, 800Hz and 1200Hz. Figure 10: [bottom] A 200Hz signal played through a system with Fcs at 400Hz, 800Hz and 1200Hz.](https://dt7v1i9vyp3mf.cloudfront.net/styles/news_large/s3/imagelibrary/s/synth9_10-0301-TZPuaf0yJH13qHXbPojxxRpy82aXARPt.gif "Figure 9: [top] A 100Hz signal played through a system with Fcs at 400Hz, 800Hz and 1200Hz. Figure 10: [bottom] A 200Hz signal played through a system with Fcs at 400Hz, 800Hz and 1200Hz.") Figure 9: [top] A 100Hz signal played through a system with Fcs at 400Hz, 800Hz and 1200Hz. Figure 10: [bottom] A 200Hz signal played through a system with Fcs at 400Hz, 800Hz and 1200Hz.The first of these shows the spectral structure of a 100Hz sawtooth wave played through a set of band-pass filters with Fcs of 400Hz, 800Hz and 1200Hz. As you can see, the harmonics that lie at 400Hz, 800Hz and 1200Hz are amplified in relation to the rest of the spectrum, thus emphasising (in this case) the fourth, eighth and 12th harmonics.
Figure 9: [top] A 100Hz signal played through a system with Fcs at 400Hz, 800Hz and 1200Hz. Figure 10: [bottom] A 200Hz signal played through a system with Fcs at 400Hz, 800Hz and 1200Hz.The first of these shows the spectral structure of a 100Hz sawtooth wave played through a set of band-pass filters with Fcs of 400Hz, 800Hz and 1200Hz. As you can see, the harmonics that lie at 400Hz, 800Hz and 1200Hz are amplified in relation to the rest of the spectrum, thus emphasising (in this case) the fourth, eighth and 12th harmonics.
The second uses exactly the same filter bank but, because the source signal has its fundamental at 200Hz (ie. one octave higher) it's the third, seventh, and 11th harmonics that are exaggerated. As one would expect, this changes the character of the sound considerably.
 Figure 11: The EQ curves of graphic equalisers are not suitable for creating tight peaks in the sound spectrum.At this point, you may be asking why you can't use a graphic equaliser (or a multi-band fixed filter such as the one shown in Figure 10) to create these distinctive peaks in your sounds' spectra. The reason for this is simple: the peaks of the equalisers that comprise a conventional filter-bank are too broad, so each filter boosts a wide range of frequencies. This is in sharp contrast to room modes and instrument modes which are, well... sharp (see Figure 11).
Figure 11: The EQ curves of graphic equalisers are not suitable for creating tight peaks in the sound spectrum.At this point, you may be asking why you can't use a graphic equaliser (or a multi-band fixed filter such as the one shown in Figure 10) to create these distinctive peaks in your sounds' spectra. The reason for this is simple: the peaks of the equalisers that comprise a conventional filter-bank are too broad, so each filter boosts a wide range of frequencies. This is in sharp contrast to room modes and instrument modes which are, well... sharp (see Figure 11).
Clearly, we need something more specialised if we are to model cavity modes using filters. But before we come to this, let's expand our horizons beyond simple peaks of fixed frequencies and fixed gains. We need to consider...
Things That Make You Go "Hmm" (Well, "Aaah" Anyway)
Let's ask ourselves what happens when the spectral peaks in the signal are less regular — ie. not evenly spaced, not all of equal gain, and not all of equal width. Furthermore, can we describe what happens when their positions (their Fcs) are not constant? To investigate this, we're going to consider the most flexible musical instrument and synthesizer of them all... the human voice.
Because you share the basic format of your sound production system with about six billion other bipedal mammals, it's safe to say that all human vocalisations — whatever the language, accent, age or gender — share certain acoustic properties. To be specific, we all push air over our vocal cords to generate a pitched signal with a definable fundamental and multiple harmonics. We can all tighten and relax these cords to change the pitch of this signal. Furthermore, we can all produce vocal noise. The pitched sounds are generated deep in our larynx, so they must pass through our throats, mouths, and noses before they reach the outside world through our lips and nostrils. And, like any other cavity, this 'vocal tract' exhibits resonant modes that emphasise some frequencies while suppressing others. In other words, the human vocal system comprises a pitch-controlled oscillator, a noise generator, and a set of band-pass filters! The resonances of the vocal tract, and the spectral peaks that they produce, are called 'formants', a word derived from the Latin 'formare', meaning 'to shape'.
Measurement and acoustic theory have demonstrated that the centre frequencies of these formants are related to simple anatomical properties such as the length and cross-section of the tube of air that comprises the vocal tract. And, since longer tubes have lower fundamentals than shorter ones, it's a fair generalisation to suppose that adult human males will have deeper voices than adult human females or human children.
Now, ignoring the sounds of consonants for a moment, it's the formants that make it possible for us to differentiate different vowel sounds from one another (consonants are, to a large degree, noise bursts shaped by the tongue and lips, and we can model these using amplitude contours rather than spectral shapes). The following table shows the first three formant frequencies (Fcs) for a range of common English vowels spoken by an adult male. Note that, unlike many of the characteristics we have discussed in the past 22 instalments of Synth Secrets, these do not follow any recognisable harmonic series. Nor do they conform to series defined by Bessel functions. This is yet another reason why the filters within graphic EQs and fixed filter banks are unsuitable. Such filters tend to be spaced regularly in octaves or fractions of octaves, whereas formants are distributed in seemingly random fashion throughout the spectrum.
| VOWEL SOUND | AS IN... | F1 | F2 | F3 |
| "ee" | leap | 270 | 2300 | 3000 |
| "oo" | loop | 300 | 870 | 2250 |
| "i" | lip | 400 | 2000 | 2550 |
| "e" | let | 530 | 1850 | 2500 |
| "u" | lug | 640 | 1200 | 2400 |
| "a" | lap | 660 | 1700 | 2400 |
Given just these three frequencies you can, with precise filters, create passable imitations of these vowel sounds. This is because (as demonstrated by experiments as long ago as the 1950s) your ears can differentiate one vowel from another with only the first three formants present. So — provided that you use an oscillator with a rich harmonic spectrum — you can patch a modular analogue synthesizer to say "eeeeeeeeee" (as shown in Figure 12). If you have almost unlimited funds and space, plus a particularly chunky power supply, you can add more formants to make the resulting sound more 'human'. With six or more formants, the results can be very lifelike indeed.
![Figure 12: [top] Say "eeeeeeeeeee". Figure 13: [bottom] Say "eeeeeeeeeee" more like a human, please.](https://dt7v1i9vyp3mf.cloudfront.net/styles/news_large/s3/imagelibrary/s/synth12_13-0301-obO2PL8gPlXwK0pq0weEtBhdm4sMTohd.gif "Figure 12: [top] Say \"eeeeeeeeeee\". Figure 13: [bottom] Say \"eeeeeeeeeee\" more like a human, please.") Figure 12: [top] Say "eeeeeeeeeee". Figure 13: [bottom] Say "eeeeeeeeeee" more like a human, please.
Figure 12: [top] Say "eeeeeeeeeee". Figure 13: [bottom] Say "eeeeeeeeeee" more like a human, please.
Mind you, in real life, things are far from this simple. Every human vocal tract is different from every other, so the exact positions of the formants differ from person to person. In addition, the amplitudes of the formants are not equal, and the widths of the formants (expressed as 'Q') vary from person to person, and from sound to sound.
Although it's tempting to shy away from mathematical expressions, Q is a simple way to express and understand the sharpness of a band-pass filter or formant, and is defined in the following formula:
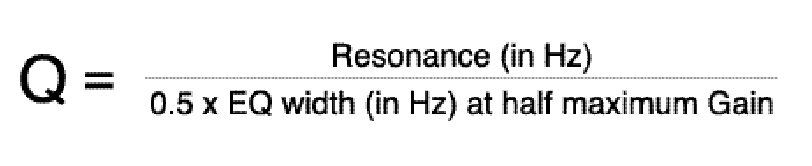
This states that you calculate the quantity 'Q' by dividing the centre frequency of the curve (in Hz) by the half-width of the EQ curve (measured at half the maximum gain).
Let's take, for example, an EQ curve with a centre frequency of 1kHz and a width (at half the maximum gain) of 200Hz. The Q would therefore be 1,000/100, which is 10. Similarly, if the centre frequency remained at 1kHz but the width was just 50Hz (a shape represented by the blue curves in Figure 11) the Q would be 40 — a very 'tight' response indeed.
Clearly, the sharper the EQ curve or formant, and the fewer frequencies that it affects in any significant fashion, the higher the quantity 'Q' becomes. Conversely, if the curve is very broad (the red curves in Figure 11) and significantly affects a wide range of frequencies, the Q is low.
Understanding this, we can extend the above table, adding amplitude information to create formants that are more accurate. Let's take "ee" as an example...
| VOWEL SOUND "EE" | GAIN (dB)> | Q |
| F1 270 | 0 | 5 |
| F2 2300 | -15 | 20 |
| F3 3000 | -9 | 50 |
The mathematically inclined among you may have noticed that these Qs (which increase with Fc) suggest a bandwidth for all the formants of around 100Hz. This is indeed the case for a man's voice, although the bandwidth increases somewhat with formant frequency. Women's formants are — as a rule — slightly wider than men's (no sniggering at the back, please).
Therefore, to make our vocal synthesizer more authentic, we must make the Qs of our band-pass filters controllable, and add a set of VCAs, as shown in Figure 13 above. Having done this, we're perfectly justified in calling our configuration a 'formant synthesizer'.
Unfortunately, this still isn't the end of the story, because the sound generated in Figure 13 is static, whereas human vowel sounds are not. We need to make the band-pass filters controllable, applying CVs to the filter Fcs and the VCAs' gains. If we analyse human speech, we find that the second formant is often the one that moves most, which suggests that this the most important clue to understanding speech. Furthermore, we would discover that the relative gains of the formants can swap... sometimes the lowest formant is the loudest, and sometimes it's the second or third.
Knowing all this suggests a novel approach to speech transmission — at least for vowel sounds. Instead of transmitting 44,100 16-bit samples per second down a line of limited bandwidth, we could send a handful of parameters — the formant frequencies, gains and Qs — once every few milliseconds, and reconstruct the voice at the other end of the line. If we restrict ourselves to, say, six formants, and update the parameters 100 times per second, we would require, at most, 1800 words of information, cutting the required bandwidth by a factor of almost 25.
Unfortunately, interesting as this is, I can see Sound On Sound's editors glowering at me from the wings. This is because, if we proceed any further down this route, we'll find ourselves firmly within speech recognition and resynthesis territory, and that's a step too far for Synth Secrets.
Practical Formant Synthesis
Just as the precise positions and shapes of the formants in a human voice allow you to recognise the identity of the speaker as well as the vowel sound spoken, the exact natures of the static formants make the timbres of a family of acoustic instruments consistent and recognisable from one instrument to the next, and over a wide range of played pitches. This is down to simple mechanics. For example, all Spanish guitars are of similar shape, size, and construction, so they possess similar formants and exhibit a consistent tonality that your ears can distinguish from say, a plucked viola playing the same pitch. It therefore follows that imitating these formants is a big step forward in realistic synthesis.
Of course, you may not have access to the room full of modules demanded by the practical configuration of Figure 13, so let's ask whether there are any simpler and cheaper ways to experiment with formant synthesis.
Firstly, although I discounted graphic EQs and fixed filters earlier in this article, there is a common type of equaliser that is quite suitable for imitating fixed formants. This is the parametric equaliser, which typically offers three controls per EQ: the centre frequency (often called the 'resonant' frequency), the gain, and the 'Q'. These, as you can see, are exactly the controls needed to perform as required in Figure 13. Sure, they're not dynamically changeable, but that's an unnecessary facility if we wish to synthesize hollow-bodied instruments such as guitars and the family of orchestral strings.
 Figure 14: A resonant multi-mode filter.In principle, you can set up a parametric EQ to impart the tonal qualities of families of instruments. This then allows you to adjust other parts of the synthesizer — such as the source waveform, a low-pass filter, or brightness and loudness contours — to fine-tune the 'virtual instrument'. For example, you could filter the waveform and shorten the contours' decays to swap between the sound of bright new guitar strings, and the dull 'thunk' that emanates from the 10-year-old rubber bands on my aged Eko 12‑string.
Figure 14: A resonant multi-mode filter.In principle, you can set up a parametric EQ to impart the tonal qualities of families of instruments. This then allows you to adjust other parts of the synthesizer — such as the source waveform, a low-pass filter, or brightness and loudness contours — to fine-tune the 'virtual instrument'. For example, you could filter the waveform and shorten the contours' decays to swap between the sound of bright new guitar strings, and the dull 'thunk' that emanates from the 10-year-old rubber bands on my aged Eko 12‑string.
But what if you want to make your synth talk? While fixed formants are sufficient for synthesizing fixed-cavity instruments, they are inadequate for vocal synthesis. We need something more powerful than a parametric EQ...
Consider the resonant multi-mode filter shown in Figure 14. This offers a band-pass mode with CV control of frequency (Fc), manual control of Level (Gain) and (if coupled to a VCA) CV control of resonance (Q). If used alongside a second VCA that provides dynamic control over amplitude, this could be a satisfactory basis for a 'formant synthesizer'.
Unfortunately, you will require three modules for each formant, with appropriate CVs for each (see Figure 15). Although you only need one set of formant filters (remember, the formants remain constant for all pitches), you'll need to be able to supply all the CVs to change the sound as the note progresses. Furthermore, since Figure 15 depicts a monophonic instrument, the complexity will increase considerably if you wish to add polyphony. This can lead rapidly to an enormous and unwieldy monstrosity. Nonetheless, there's no reason why it should not produce, say, a recognisable "aaaa" sound which, by suitable manipulation of the CVs, changes smoothly to an "eeee" sound.
 Figure 15: Part of a formant synthesizer constructed from multi-mode filters.
Figure 15: Part of a formant synthesizer constructed from multi-mode filters.
But The Sensible Solution Is...
We've encountered this spiralling complexity once before in Synth Secrets. It was when we discussed a polyphonic analogue FM synthesizer. While possible, this proved to be totally impractical, and the solution was found in the digital FM technology pioneered by Yamaha and incorporated to such devastating commercial effect in the DX7.
 Yamaha FS1R formant synthesizer.Well, we're going to the same source for the solution to the complexities of formant synthesis. While it has had far less impact than the DX7, Yamaha's FS1R (reviewed SOS December 1998) is a superb and under-rated synthesizer designed specifically to imitate the moving formants found in speech, as well as the fixed-frequency formants of acoustic instruments. It even incorporates unpitched operators that can imitate consonants, as well as produce percussion and drum sounds. With real-time processing of the formants' Fc, Gain, Q, and a parameter called 'skirt', it is quite capable of emulating words and phrases — something that you would need a huge assembly of analogue modules to achieve.
Yamaha FS1R formant synthesizer.Well, we're going to the same source for the solution to the complexities of formant synthesis. While it has had far less impact than the DX7, Yamaha's FS1R (reviewed SOS December 1998) is a superb and under-rated synthesizer designed specifically to imitate the moving formants found in speech, as well as the fixed-frequency formants of acoustic instruments. It even incorporates unpitched operators that can imitate consonants, as well as produce percussion and drum sounds. With real-time processing of the formants' Fc, Gain, Q, and a parameter called 'skirt', it is quite capable of emulating words and phrases — something that you would need a huge assembly of analogue modules to achieve.
![Figure 16: [top] A typical frequency response from a resonant low-pass filter. Figure 17: [bottom] Imitating a resonant low-pass filter using two formants.](https://dt7v1i9vyp3mf.cloudfront.net/styles/news_large/s3/imagelibrary/s/synth16_17-0301-svHJ0zJXLRBfnrlbY1.Kz0c3sXrSNWEb.gif "Figure 16: [top] A typical frequency response from a resonant low-pass filter. Figure 17: [bottom] Imitating a resonant low-pass filter using two formants.") Figure 16: [top] A typical frequency response from a resonant low-pass filter. Figure 17: [bottom] Imitating a resonant low-pass filter using two formants.Finally, let's take a look at how the FS1R imitates the frequency response of a harmonically rich signal (or noise) passed through a resonant low-pass analogue filter (see Figure 16). Yes, yes... we've seen it all before, but bear with me one more time.
Figure 16: [top] A typical frequency response from a resonant low-pass filter. Figure 17: [bottom] Imitating a resonant low-pass filter using two formants.Finally, let's take a look at how the FS1R imitates the frequency response of a harmonically rich signal (or noise) passed through a resonant low-pass analogue filter (see Figure 16). Yes, yes... we've seen it all before, but bear with me one more time.
Surprisingly, we can reconstruct this frequency response using just two formants — one with a centre frequency of 0Hz and a Q of, say 0.1, and one with a centre frequency equal to the analogue filter's Fc, and with a Q of, say, 10 (see Figure 17).
The result is remarkable. What's more, we can make the formant-generated sound respond very similarly to the analogue case. To be specific, we can shift the perceived cutoff frequency by moving the centre frequency of the upper formant while narrowing the Q of the lower formant by an appropriate amount. Do this in real time, and you have a sweepable filter. Furthermore, we can increase and decrease the perceived resonance by increasing or decreasing the amplitude of the upper formant alone.
So, as has happened so many times before, we've come full circle. Analogue and digital synthesis — in this case, digital formant synthesis — are simply different ways of achieving similar results. So what else is new?
Footnote
Next month we reach Synth Secrets Part 24... which means we've gone through nearly two years of investigation into some of the fundamentals of sound and synthesis. Not surprisingly, we've covered many of the major aspects of the subject, so it's time to ask, "is this the end of our odyssey?".
Not a bit of it. However, from now on, we're going to turn things on their head. Instead of delving into some esoteric aspect of acoustics or electronics and seeing where it takes us, we're going to select a family of orchestral instruments and see how we can emulate them using our synthesizers. In other words, we're finally going to get our hands dirty with a bit of genuine synthesis. And where there's muck, there's brass...